সিস্টেম ডিজাইন ইন্টারভিউতে কোড লেখার চেয়ে বেশি দেখা হয় আপনি কীভাবে পুরো সিস্টেমটিকে ডিজাইন করছেন। সিস্টেম ডিজাইন মানে হলো এমন একটি ব্যবস্থা তৈরি করা যা কেবল মসৃণভাবে চলে না, বরং ব্যর্থতার জন্যেও পরিকল্পনা (planning for failure) করে এবং ইউজার বাড়ার সাথে সাথে নিজেকে বড় করতে পারে।
এই গাইডে আমরা সিস্টেম ডিজাইনের প্রতিটি খুঁটিনাটি বিষয় সহজ বাংলায় বিস্তারিত আলোচনা করব।
১. কম্পিউটারের আর্কিটেকচার (High-Level Architecture of an Individual Computer)
বড় কোনো ডিস্ট্রিবিউটেড সিস্টেম বানানোর আগে একটা সিঙ্গেল কম্পিউটার কীভাবে কাজ করে সেটা বোঝা খুব জরুরি। কম্পিউটার স্তরে স্তরে (layered) কাজ করে, যেখানে প্রতিটি স্তরের কাজ আলাদা।
ডেটা স্টোরেজ ও মেমরি লেয়ার

কম্পিউটার মানুষের ভাষা বোঝে না, সে শুধু বাইনারি ০ আর ১ বোঝে।
- Bit (বিট): কম্পিউটিং-এর সবচেয়ে ক্ষুদ্রতম ইউনিট (০ অথবা ১)।
- Byte (বাইট): আটটি বিট মিলে ১ বাইট গঠিত হয়, যা দিয়ে একটি অক্ষর (character) বা সংখ্যা বোঝানো হয়।
মেমরি বা স্টোরেজ স্পিড এবং কাজের ধরন অনুযায়ী কয়েক ভাগে ভাগ করা যায়:
১. ডিস্ক স্টোরেজ (Disk Storage - HDD/SSD): এটি হলো কম্পিউটারের পার্মানেন্ট স্টোরেজ। বিদ্যুৎ চলে গেলেও এখানকার ডেটা মুছে যায় না। এখানে অপারেটিং সিস্টেম, অ্যাপ এবং আপনার ফাইলগুলো থাকে।
- HDD (Hard Disk Drive): এর ভেতরে যান্ত্রিক চাকা ঘোরে, তাই এটি কিছুটা ধীরগতির (৮০-১৬০ MB/s)।
- SSD (Solid State Drive): এটি চিপ-ভিত্তিক, তাই HDD-এর চেয়ে অনেক গুণ ফাস্ট (৫০০-৩৫০০ MB/s)। আধুনিক সার্ভারে ডাটাবেসের জন্য SSD ব্যবহার করা হয় যাতে দ্রুত ডেটা রিড/রাইট করা যায়।
২. র্যাম (RAM - Random Access Memory): এটি ডিস্কের চেয়ে অনেক বেশি ফাস্ট। আমরা যখন কোনো অ্যাপ বা গেম ওপেন করি, তখন সেটার ডেটা ডিস্ক থেকে র্যামে লোড হয় যাতে প্রসেসর দ্রুত কাজ করতে পারে।
- বৈশিষ্ট্য: এটি ভোলাটাইল (Volatile)—অর্থাৎ কম্পিউটার বন্ধ করলে বা রিস্টার্ট দিলে র্যামের সব ডেটা মুছে যায়। এর স্পিড ৫০০০ MB/s এর বেশি হতে পারে।
৩. ক্যাশ (Cache): এটি র্যামের চেয়েও ফাস্ট এবং CPU-এর একদম ভেতরে বা খুব কাছে থাকে।
- L1, L2, L3 Cache: CPU যখন কোনো কাজ করে, সে বারবার র্যামে না গিয়ে সবচেয়ে বেশি ব্যবহৃত ডেটাগুলো এই ক্যাশ মেমোরিতে জমা রাখে। L1 ক্যাশের অ্যাক্সেস টাইম মাত্র কয়েক ন্যানোসেকেন্ড।
- উদাহরণ: র্যাম যদি হয় লাইব্রেরি, তবে ক্যাশ হলো আপনার পড়ার টেবিল। টেবিলে রাখা বই আপনি লাইব্রেরির চেয়ে দ্রুত হাতের কাছে পান।
৪. CPU (Central Processing Unit): এটি কম্পিউটারের মস্তিষ্ক। এটি মেমরি থেকে নির্দেশ (Instruction) নেয়, সেটা বোঝে (Decode) এবং কাজটা করে (Execute)। জাভা বা পাইথনের কোড কম্পাইলারের মাধ্যমে মেশিন কোডে পরিণত হয়, যা CPU চালাতে পারে।
২. প্রোডাকশন অ্যাপ আর্কিটেকচার (Production-Ready Architecture)
আমরা যখন ল্যাপটপে কোড করি (Local Environment), তখন সব কিছু একটা মেশিনে থাকে। কিন্তু যখন সেটা প্রোডাকশনে বা লাইভ সার্ভারে যায়, তখন আর্কিটেকচারটা অনেক জটিল হয়। একটি প্রোডাকশন-রেডি অ্যাপে নিচের কম্পোনেন্টগুলো থাকে:
১. CI/CD পাইপলাইন (Continuous Integration & Deployment): আগে মানুষ ম্যানুয়ালি সার্ভারে কোড আপলোড করত, যা ছিল ঝুঁকিপূর্ণ। এখন Jenkins বা GitHub Actions ব্যবহার করা হয়।
- আপনি কোড পুশ করার সাথে সাথে সেটা অটোমেটিক টেস্ট হয়।
- টেস্ট পাস করলে সেটা বিল্ড হয় এবং সার্ভারে লাইভ হয়ে যায়। এতে ভুলের সম্ভাবনা কমে।
২. লোড ব্যালেন্সার ও রিভার্স প্রক্সি (Load Balancer):

ধরুন আপনার অ্যাপে ১০০০ জন ইউজার এসেছে, একটা সার্ভার সেটা সামলাতে পারছে। কিন্তু ১ লক্ষ ইউজার আসলে সার্ভার ক্র্যাশ করবে। তখন আমরা একাধিক সার্ভার ব্যবহার করি।
- কাজ: লোড ব্যালেন্সার (যেমন Nginx) ট্রাফিক পুলিশের মতো কাজ করে—সে আগত ইউজারদের বিভিন্ন সার্ভারে সমানভাবে ভাগ করে দেয়। এতে কোনো একটি সার্ভারের ওপর চাপ পড়ে না।
৩. লগিং, মনিটরিং ও অ্যালার্টিং: সার্ভারে কখন কী সমস্যা হচ্ছে তা জানার জন্য Sentry, Datadog বা Pm2 এর মতো টুল ব্যবহার করা হয়।
- Logging: সিস্টেমে কী ঘটছে তার রেকর্ড রাখা।
- Monitoring: সার্ভারের CPU বা RAM কতটুকু ব্যবহার হচ্ছে তা দেখা।
- Alerting: কোনো এরর হলে বা সার্ভার ডাউন হলে সাথে সাথে ডেভেলপারকে Slack বা ইমেইলে জানানো।
- গোল্ডেন রুল: প্রোডাকশন এনভায়রনমেন্টে কখনো সরাসরি ডিবাগ করবেন না। সমস্যাটি আগে নিজের মেশিনে বা টেস্ট সার্ভারে রি-ক্রিয়েট করুন। যদি ইমার্জেন্সি হয়, তবে Hot Fix (দ্রুত সমাধান) দিয়ে পরে পার্মানেন্ট সলিউশন করা হয়।
৩. সিস্টেম ডিজাইনের পিলার ও CAP থিওরেম
একটি ভালো সিস্টেম দাঁড় করাতে হলে ৪টি মূল স্তম্ভের ওপর জোর দিতে হয়:
- Scalability (স্কেলেবিলিটি): ইউজার বাড়লে সিস্টেমও বড় করা যাবে।
- Maintainability (মেইনটেনেবিলিটি): কোড এমনভাবে লেখা যেন ভবিষ্যতে অন্য কেউ এসে সহজে কাজ করতে পারে।
- Efficiency (এফিসিয়েন্সি): কম রিসোর্স (CPU/RAM) ব্যবহার করে সর্বোচ্চ আউটপুট দেওয়া।
- Reliability (রিলায়বিলিটি): সিস্টেম যেন হুটহাট ক্র্যাশ না করে এবং ভুল হলেও রিকভার করতে পারে (Fault Tolerance)।
CAP Theorem: ডিস্ট্রিবিউটেড সিস্টেমের গোল্ডেন রুল
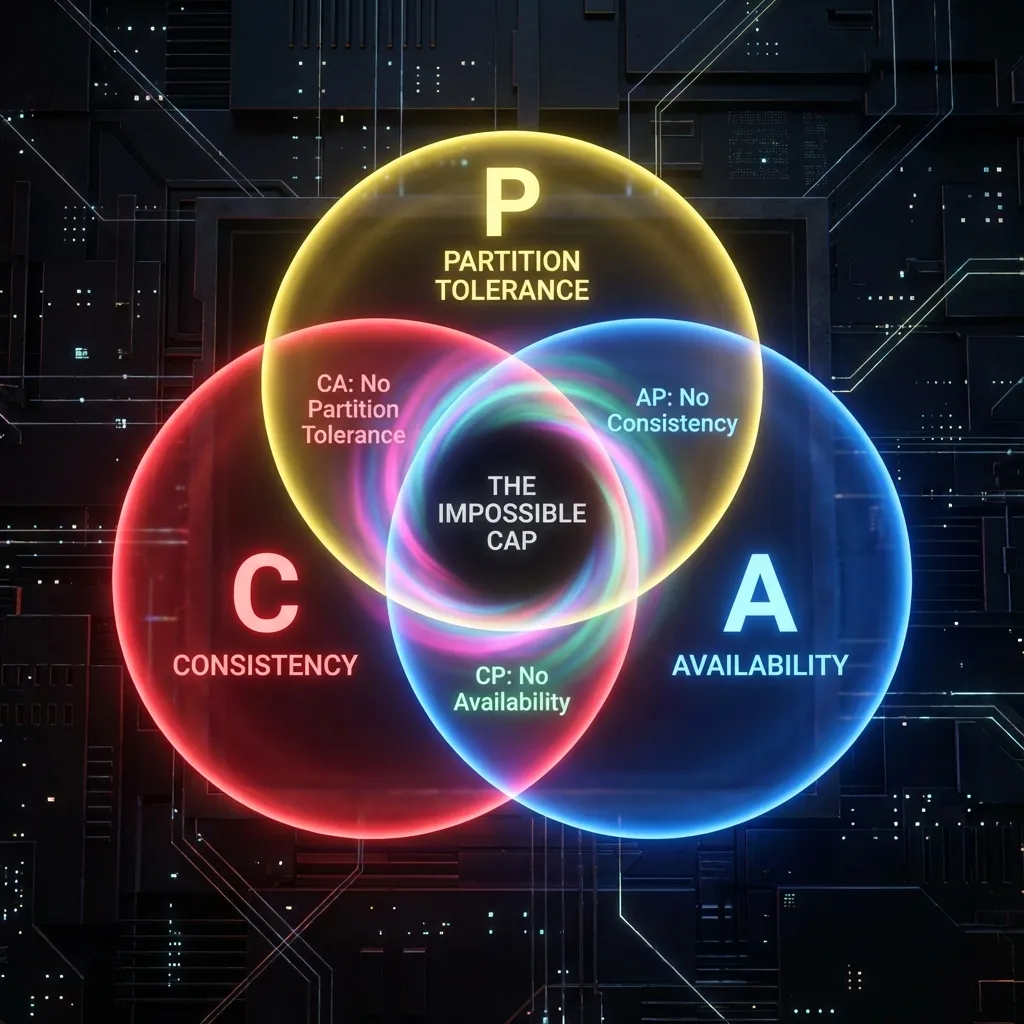
যখন আমরা অনেকগুলো সার্ভার বা নোড নিয়ে কাজ করি, তখন CAP Theorem বলে যে আমরা একসাথে ৩টি জিনিস পাবো না, যেকোনো ২টি বেছে নিতে হবে:
- Consistency (C): সব ইউজার একই সময়ে একই ডেটা দেখবে। (যেমন: আপনি টাকা পাঠালেন, সাথে সাথে আপনার এবং প্রাপকের ব্যালেন্স আপডেট হতে হবে)।
- Availability (A): সিস্টেম সবসময় সচল থাকবে এবং রেসপন্স করবে। কোনো এরর দেখাবে না।
- Partition Tolerance (P): নেটওয়ার্কের কোনো তার কাটা গেলে বা সার্ভার বিচ্ছিন্ন হলেও সিস্টেম চলবে।
বাস্তব উদাহরণ ও ট্রেড-অফ:
- ব্যাংকিং সিস্টেম (CP): এখানে Consistency এবং Partition Tolerance বেশি জরুরি। টাকা জমার সাথে সাথে ব্যালেন্স আপডেট হতে হবে। সার্ভার ডাউন থাকলেও ভুল ব্যালেন্স দেখানো যাবে না। তাই প্রয়োজনে সিস্টেম কিছুক্ষণের জন্য Unavailable হতে পারে, কিন্তু ভুল তথ্য দেবে না।
- সোশ্যাল মিডিয়া (AP): এখানে Availability এবং Partition Tolerance বেশি জরুরি। আপনার বন্ধুর লাইক আপনি ৫ সেকেন্ড পরে দেখলেও সমস্যা নেই (Consistency কম), কিন্তু অ্যাপ ওপেন না হলে বা পোস্ট না দেখা গেলে ইউজার বিরক্ত হবে।
৪. সিস্টেমের মেট্রিক্স (Metrics)
সিস্টেম কেমন পারফর্ম করছে তা মাপার জন্য কিছু স্ট্যান্ডার্ড মেট্রিক্স আছে:
- Availability: সিস্টেমটি বছরে কতক্ষণ চালু থাকে। 99.999% (Five Nines) অ্যাভেইলিবিলিটি মানে বছরে মাত্র ৫ মিনিট ডাউনটাইম।
- Throughput: সিস্টেম প্রতি সেকেন্ডে কতগুলো রিকোয়েস্ট হ্যান্ডেল করতে পারে (RPS - Requests Per Second) বা কত ডেটা প্রসেস করতে পারে।
- Latency: একটা রিকোয়েস্ট সার্ভারে গিয়ে রেসপন্স হয়ে ফিরে আসতে কত সময় লাগে।
- ট্রেড-অফ: অনেক সময় থ্রুপুট বাড়াতে গেলে লেটেন্সি বেড়ে যায় (যেমন ব্যাচ প্রসেসিং)।
- SLA (Service Level Agreement): এটি ক্লায়েন্টের সাথে একটি আইনি চুক্তি। যেমন: “আমরা ৯৯.৯% সময় সার্ভিস চালু রাখব, না পারলে জরিমানা দেব।”
- SLO (Service Level Objective): এটি আমাদের নিজেদের সেট করা গোল (যেমন: আমরা চাই ৯৯.৯% রিকোয়েস্ট ৩০০ms এর মধ্যে রেসপন্স করুক)।
৫. নেটওয়ার্কিং ও প্রোটোকল (Networking & Protocols)
ইন্টারনেটে এক কম্পিউটার অন্য কম্পিউটারের সাথে কীভাবে কথা বলে?
IP Address, Packets & Ports
- IP Address: প্রতিটি ডিভাইসের একটা ঠিকানা থাকে। IPv4 (যেমন
192.168.1.1) এবং নতুন IPv6।- Public IP: ইন্টারনেটে ইউনিক।
- Private IP: আপনার লোকাল নেটওয়ার্কের ভেতর (যেমন অফিসের ওয়াইফাই)।
- Packets: ডেটা পুরোটা একসাথে যায় না, ছোট ছোট টুকরো বা প্যাকেট আকারে যায়।
- Ports: একই আইপিতে অনেক সার্ভিস চলতে পারে। পোর্ট দিয়ে তাদের আলাদা করা হয়। যেমন ওয়েব সার্ভার চলে Port 80 (HTTP) বা 443 (HTTPS) এ, আর SSH চলে Port 22 এ।
- Firewall: এটি গেটকিপারের মতো। কোন পোর্টে ট্রাফিক ঢুকবে আর কোনটা ব্লক হবে তা ঠিক করে।
TCP vs UDP
ডেটা পাঠানোর দুটি প্রধান নিয়ম বা প্রোটোকল আছে:
১. TCP (Transmission Control Protocol):
- এটি খুব নির্ভরযোগ্য। ডেটা হারাবে না, এবং অর্ডারে পৌঁছাবে।
- ডেটা পাঠানোর আগে কানেকশন তৈরি করে (Three-way handshake)।
- ব্যবহার: ওয়েব ব্রাউজিং, ইমেইল, ফাইল ট্রান্সফার (যেখানে এক বিট ডেটা হারালেও ফাইল নষ্ট হয়ে যাবে)।
২. UDP (User Datagram Protocol):
- এটি নির্ভরযোগ্যতার চেয়ে গতির দিকে বেশি নজর দেয়। ডেটা প্যাকেট হারালেও সমস্যা নেই।
- কোনো কানেকশন তৈরি করে না, সরাসরি ডেটা পাঠাতে থাকে।
- ব্যবহার: ভিডিও কল, লাইভ স্ট্রিমিং, অনলাইন গেমিং। (ভিডিও কলে এক ফ্রেম হারালে সমস্যা নেই, কিন্তু দেরি হলে ল্যাগ হবে)।
৬. API ডিজাইন (API Design)
API (Application Programming Interface) হলো অ্যাপের ফ্রন্টএন্ড এবং ব্যাকএন্ডের মধ্যে যোগাযোগের মাধ্যম।
CRUD অপারেশন ও HTTP মেথড
অধিকাংশ অ্যাপে ৪টি মূল কাজ থাকে:
- Create (তৈরি):
POSTমেথড। (যেমন:/api/users) - Read (পড়া):
GETমেথড। এটি Idempotent হওয়া উচিত—অর্থাৎ একই রিকোয়েস্ট বারবার দিলেও সার্ভারের ডেটা চেঞ্জ হবে না। - Update (আপডেট):
PUT(পুরোটা আপডেট) বাPATCH(আংশিক আপডেট)। - Delete (মুছে ফেলা):
DELETEমেথড।
HTTP Status Codes
সার্ভার রেসপন্সের সাথে একটি কোড পাঠায় যা বলে দেয় রিকোয়েস্টের অবস্থা কী:
- 200 Series (Success): সব ঠিক আছে (যেমন 200 OK, 201 Created)।
- 300 Series (Redirection): অন্য কোথাও যেতে হবে।
- 400 Series (Client Error): ইউজারের ভুল (যেমন 400 Bad Request, 401 Unauthorized, 404 Not Found)।
- 500 Series (Server Error): সার্ভারের সমস্যা (যেমন 500 Internal Server Error)।
API প্যারাডাইম
- REST: স্ট্যান্ডার্ড HTTP মেথড ব্যবহার করে। সহজ কিন্তু মাঝে মাঝে বেশি ডেটা (Over-fetching) বা কম ডেটা (Under-fetching) নিয়ে আসে।
- GraphQL: এখানে ক্লায়েন্ট বলে দেয় তার ঠিক কী কী ফিল্ড দরকার। এতে নেটওয়ার্ক ব্যান্ডউইথ বাঁচে।
- gRPC: এটি Google-এর তৈরি। এটি JSON-এর বদলে Protocol Buffers ব্যবহার করে, যা অনেক ফাস্ট। মাইক্রোসার্ভিসে এটি বেশি ব্যবহৃত হয়।
Best Practices
- Rate Limiting: একজন ইউজার নির্দিষ্ট সময়ে কতবার রিকোয়েস্ট করতে পারবে তা লিমিট করা (DDoS অ্যাটাক ঠেকাতে)।
- CORS: অন্য ডোমেইন থেকে আপনার API কল করা যাবে কিনা তা নিয়ন্ত্রণ করা।
৭. ক্যাশিং ও CDN (Caching & CDN)
সিস্টেমকে সুপার ফাস্ট করার গোপন অস্ত্র হলো ক্যাশিং।
ক্যাশিং লেয়ার ও পলিসি
যে ডেটাগুলো বারবার লাগে, সেগুলো ডাটাবেস থেকে বারবার না এনে মেমোরিতে রেখে দেওয়া হয়।
- Browser Cache: ব্রাউজার লোগো, CSS ফাইল সেভ করে রাখে।
- Server Cache (Redis/Memcached): ডাটাবেস কোয়েরির রেজাল্ট সার্ভারের র্যামে রেখে দেওয়া হয়।
- Eviction Policies: ক্যাশ মেমোরি ফুল হয়ে গেলে কোন ডেটা ডিলিট হবে?
- LRU (Least Recently Used): যেটা অনেকক্ষণ ধরে ব্যবহার হয়নি সেটা ডিলিট হবে।
- FIFO (First In First Out): যেটা আগে ঢুকেছে সেটা আগে বের হবে।
CDN (Content Delivery Network)
আপনার সার্ভার আমেরিকায়, কিন্তু ইউজার বাংলাদেশে। ইমেজ বা ভিডিও লোড হতে দেরি হবেই। CDN ব্যবহার করলে আপনার ওয়েবসাইটের কপি পৃথিবীর বিভিন্ন প্রান্তে থাকা সার্ভারে রাখা হয়।
- Pull CDN: ইউজার যখন প্রথমবার চায়, তখন CDN মেইন সার্ভার থেকে এনে সেভ করে রাখে।
- Push CDN: আপনি নিজেই ফাইল আপলোড করে দেন CDN এ।
৮. লোড ব্যালেন্সার ও প্রক্সি (Load Balancer & Proxy)
Proxy Server
- Forward Proxy: এটি ক্লায়েন্টের সামনে থাকে। যেমন VPN ব্যবহার করলে আপনার আসল আইপি সার্ভার জানতে পারে না। এটি দিয়ে কন্টেন্ট ফিল্টারও করা যায় (যেমন অফিসে ফেসবুক ব্লক করা)।
- Reverse Proxy: এটি সার্ভারের সামনে থাকে। ক্লায়েন্ট জানে না সে আসলে কোন সার্ভারের সাথে কথা বলছে। এটি নিরাপত্তা, SSL এনক্রিপশন এবং লোড ব্যালেন্সিংয়ের জন্য ব্যবহৃত হয়।
লোড ব্যালেন্সিং অ্যালগরিদম
- Round Robin: একে একে সবাইকে রিকোয়েস্ট পাঠানো (১ম -> ২য় -> ৩য় -> আবার ১ম)।
- Least Connections: যার কাছে কাজ কম, তাকেই নতুন রিকোয়েস্ট দেওয়া।
- IP Hashing: নির্দিষ্ট ইউজারকে সবসময় নির্দিষ্ট সার্ভারে পাঠানো (যেমন শপিং কার্ট সেশন ধরে রাখতে)।
- Weighted: শক্তিশালী সার্ভারকে বেশি রিকোয়েস্ট দেওয়া।
৯. ডাটাবেস ডিজাইন ও স্কেলিং (Database Design)
সিস্টেম ডিজাইনের অন্যতম গুরুত্বপূর্ণ অংশ হলো সঠিক ডাটাবেস নির্বাচন করা।
SQL vs NoSQL
- SQL (Relational): যেমন MySQL, PostgreSQL। এখানে ডেটা টেবিল আকারে থাকে। স্ট্রাকচার্ড ডেটার জন্য সেরা।
- ACID Properties:
- Atomicity: ট্রানজেকশন পুরোটা হবে, নাহলে কিছুই হবে না (All or Nothing)।
- Consistency: ডেটা সবসময় ভ্যালিড থাকবে।
- Isolation: একাধিক ট্রানজেকশন একে অপরকে ডিস্টার্ব করবে না।
- Durability: একবার সেভ হলে সেটা পার্মানেন্ট।
- ACID Properties:
- NoSQL (Non-Relational): যেমন MongoDB, Cassandra। এখানে ডেটা ডকুমেন্ট বা কি-ভ্যালু পেয়ার হিসেবে থাকে। আনস্ট্রাকচার্ড ডেটা বা খুব দ্রুত স্কেলিংয়ের জন্য ভালো।
ডাটাবেস স্কেলিং
ডাটাবেস বড় করার দুটি উপায় আছে:
১. Vertical Scaling (Scale Up): সার্ভারের RAM বা CPU বাড়ানো। কিন্তু এর একটা লিমিট আছে এবং খরচ অনেক বেশি।
২. Horizontal Scaling (Scale Out): নতুন সার্ভার যোগ করা।
- Sharding: বড় ডাটাবেসকে ভেঙে ছোট ছোট টুকরো করে আলাদা সার্ভারে রাখা।
- Range Based: ‘A-M’ এক সার্ভারে, ‘N-Z’ অন্য সার্ভারে।
- Geo Based: আমেরিকার ইউজারদের ডেটা আমেরিকার সার্ভারে।
- Replication (Master-Slave):
- Master DB: সব নতুন ডেটা এখানে লেখা হয় (Write Operation)।
- Slave DB: এখান থেকে শুধু ডেটা পড়া হয় (Read Operation)। মাস্টার থেকে ডেটা অটোমেটিক স্লেভে কপি হয়। এতে রিড স্পিড অনেক বেড়ে যায় এবং মাস্টার নষ্ট হলে স্লেভ ব্যাকআপ হিসেবে কাজ করে।
সিস্টেম ডিজাইন একদিনে শেখার বিষয় নয়। তবে এই বেসিক কনসেপ্টগুলো জানলে আপনি যেকোনো বড় সিস্টেমের আর্কিটেকচার বুঝতে পারবেন এবং ইন্টারভিউতে আত্মবিশ্বাসের সাথে উত্তর দিতে পারবেন। শুভকামনা!